Last updated July 16, 2025
The Unix process model is a simple and powerful abstraction for running server-side programs. It provides a helpful way to think about dividing a web app’s workloads and scaling it up over time. Heroku uses the process model for web, worker, and all other types of dynos.
Basics
Let’s begin with a simple illustration of the basics of the process model, using a well-known Unix daemon: memcached.
First, download and compile memcached using the appropriate steps for your platform.
Then, run the program:
$ ./memcached -vv
...
<17 server listening (auto-negotiate)
<18 send buffer was 9216, now 3728270
This running program is called a process.
Running a process manually in a terminal is fine for local development, but in a production deployment, your app’s processes should be managed. Managed processes should run automatically when the operating system starts up and should be restarted if the system fails for any reason.
In traditional server-based deployments, the operating system provides a process manager. On macOS, the built-in process manager is called launchd; on Ubuntu, systemd is the built-in process manager. On Heroku, the dyno manager provides an analogous mechanism.
Now that we’ve established a baseline for the process model, we can put its principles to work in more novel way: running a web app.
Mapping the Unix process model to web apps
A server daemon like memcached has a single entry point, meaning there’s only one command you run to invoke it. Web apps, on the other hand, typically have two or more entry points. Each of these entry points can be called a process type.
A basic Rails app typically has two process types: a Rack-compatible web process type (such as Webrick or Unicorn), and a worker process type that uses a queueing library (such as Delayed Job or Resque). For example:
| Process type | Command |
|---|---|
| web | bundle exec rails server |
| worker | bundle exec rake jobs:work |
A basic Django app looks similar: a web process type can be run with the manage.py admin tool, and background jobs via Celery:
| Process type | Command |
|---|---|
| web | python manage.py runserver |
| worker | celeryd --loglevel=INFO |
For a Java app, process types might look like this:
| Process type | Command |
|---|---|
| web | java $JAVA_OPTS -jar web/target/dependency/webapp-runner.jar --port $PORT web/target/*.war |
| worker | sh worker/target/bin/worker |
Process types differ for each app. For example, some Rails apps use Resque instead of Delayed Job, or they have multiple types of workers. Every Heroku app declares its own process types.
You declare your Heroku app’s process types in a special file called the Procfile that lives in your app’s root directory. The heroku local CLI command makes it easy to run the commands defined in your Procfile in your development environment. Read the Procfile documentation for details.
Process types vs dynos
To scale up, we’ll want a full grasp of the relationship between process types and dynos.
A process type is the prototype from which one or more dynos are instantiated. This is similar to the way a class is the prototype from which one or more objects are instantiated in object-oriented programming.
Here’s a visual aid showing the relationship between dynos (on the vertical axis) and process types (on the horizontal axis):
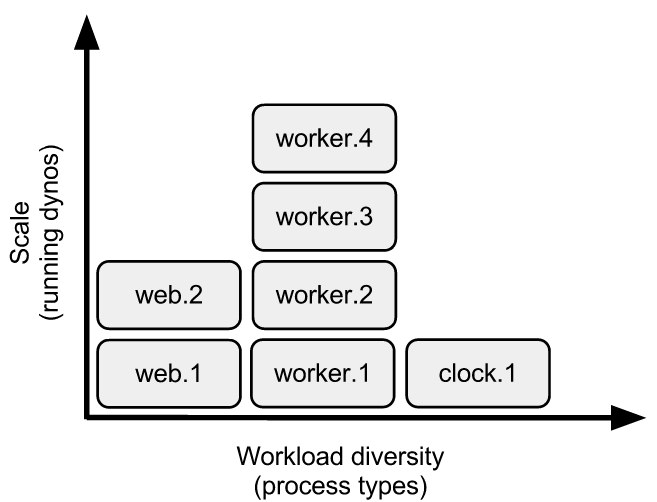
Dynos, on the vertical axis, are scale. You increase this direction when you need to scale up your concurrency for the type of work handled by that process type. On Heroku, you do this with the scale command:
$ heroku ps:scale web=2 worker=4 clock=1
Scaling web processes... done, now running 2
Scaling worker processes... done, now running 4
Scaling clock processes... done, now running 1
Process types, on the horizontal axis, are workload diversity. Each process type specializes in a certain type of work.
For example, some apps have two types of workers, one for urgent jobs and another for long-running jobs. By subdividing into more specialized workers, you can get better responsiveness on your urgent jobs and more granular control over how to spend your compute resources. A queueing system can be used to distribute jobs to the worker dynos.
Scheduling processes
Scheduling work at a certain time of day, or time intervals, much like cron does, can be achieved with a tool like the Heroku Scheduler add-on or by using a specialized job-scheduling process type.
One-off admin dynos
The set of dynos run by the dyno manager via heroku ps:scale are known as the dyno formation - for example, web=2 worker=4 clock=1. In addition to these dynos, which run continually, the process model also allows for one-off dynos to handle administrative tasks, such as database migrations and console sessions.
Read more about one-off dynos.
Output streams as logs
All code running on dynos under the process model should send their logs to STDOUT. Locally, output streams from your processes are displayed in your terminal. On Heroku, output streams from processes executing on all your dynos are collected together by Logplex for easy viewing with the heroku logs command.